深度学习工具¶
灵闪深度学习工具加载由 IntelliBlinkAI(山君)训练导出的深度学习模型,进行推理预测。可与 IntelliBlinkAI 互联进行模型验证,将灵闪处理后的图片导出回训练端。
使用前提:需安装 AI 扩展包(CPU 版或 NVIDIA GPU 版)。GPU 版包含 CPU 版的全部功能(OCR 字符识别除外),无需同时安装两版本;如确需共存,先装 CPU 再装 GPU。
工具升级历史¶
- 灵闪 3.7.40:推理后端升级
- 灵闪 3.7.57:GPU 深度学习新增批量推理、TRT 缓存
- 灵闪 3.7.62:显卡推理模型卸载的显存清理
- 灵闪 3.8.15:新增异常分割(无监督模型),推理端支持 ORT-CPU/GPU
- 灵闪 3.8.18:模型加载与预跑图前移到加载解决方案时(原为首次作业执行时)
- 灵闪 3.8.20:目标检测支持 16 位图片推理
- 灵闪 3.8.25:目标检测批量推理新增「多 ROI」「多作业多 ROI」
- 灵闪 3.8.32:目标检测工具支持结果排序
- 灵闪 3.8.38:新增字符识别工具
- 灵闪 3.8.45:字符识别工具支持训练
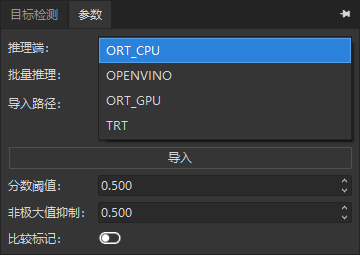
推理端¶
支持四种推理端:
- ORT_CPU(onnxruntime CPU)—— Microsoft 开发的跨平台推理和训练加速器,硬件兼容性广
- OPENVINO —— Intel 开发的开源 AI 推理优化工具包,用在 Intel CPU 与集成 GPU 上
- ORT_GPU(onnxruntime GPU)
- TRT(TensorRT)—— Nvidia 高性能深度学习推理 SDK,用于 Nvidia 显卡
选取建议¶
- CPU 上推理:较新的处理器 OPENVINO 通常更快,老处理器上 ORT_CPU 略快;实测对比择优
- GPU 上推理:TRT 推理速度优于 ORT_GPU,但 ORT_GPU 加载更快、适合日常测试调试,正式部署用 TRT
显卡编号¶
-
推理端选 ORT-GPU 或 TRT 时会出现「显卡编号」输入框
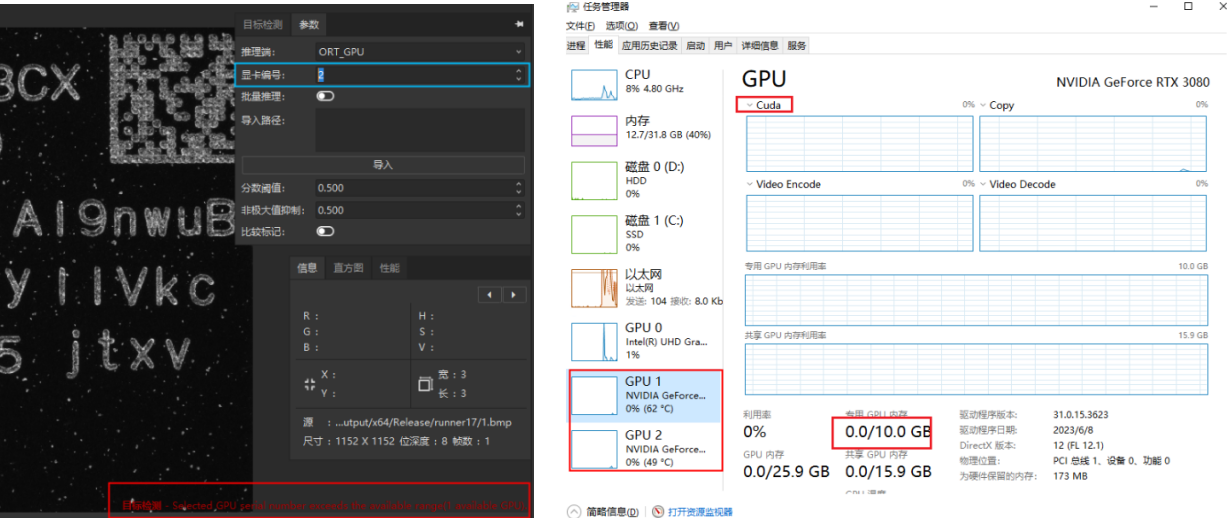
-
编号从 0 开始;填写的编号无对应显卡时会提示可用显卡数;继续导入模型工具会初始化失败

-
灵闪的显卡编号和 Windows 任务管理器里的显卡编号 不是对应关系,需通过显存占用、CUDA 占用观察实际指向

半精度(FP16)¶
- ORT 半精度:CPU 上 FP16 不会更快;GPU 上有 TRT 走半精度路线,因此 ORT_GPU 没暴露 FP16 开关
- TRT 半精度:推理端选 TRT 时会出现 FP16 开关。半精度比单精度耗时更短、显存占用更少;但 加载时间更长:TRT 单精度首次加载约 3–5 分钟,半精度约 5–7 分钟(与显卡、模型大小有关)
TRT 缓存¶
- TRT 加载时间长是因为要做模型序列化与量化;第二次加载直接读缓存,3–5 秒完成
- 缓存目录命名规则:原模型文件夹叫「模型 1」,则缓存为
.模型1.cache.trt - 缓存对应规则:缓存文件夹 + 显卡型号 + 批量推理尺寸 + 单/半精度 共同决定
- 缓存文件命名示例:
NVIDIA GeForce GTX 1660 SUPER_fp32_b2_cache.trt - 缓存仅适用相同显卡型号;CUDA / TensorRT 版本不同时缓存失效需重建
批量推理¶
为降低显存/内存占用并优化推理耗时,提供四种模式:
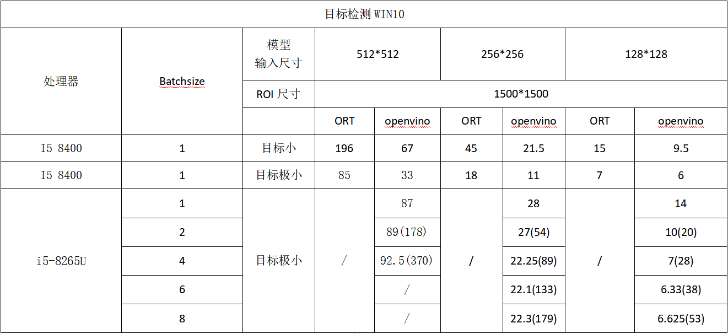
不开启¶
单张图片直接推理。如果有多个 ROI,会取多个 ROI 的外接矩形范围图片进行推理。
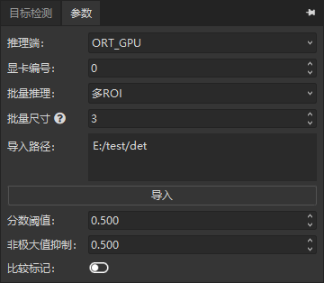
多 ROI¶
同一作业内的多个 ROI 一起批量推理。批量尺寸 = 每批同时推理的图片数。
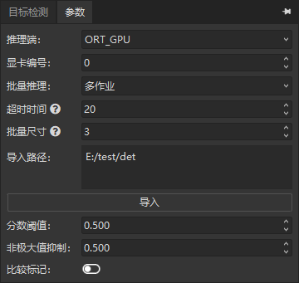
- 4 个 ROI,批量尺寸 4 → 一次推理 4 张
- 3 个 ROI,批量尺寸 4 → 一次推理 3 张
- 5 个 ROI,批量尺寸 4 → 分两次:4 张 + 1 张
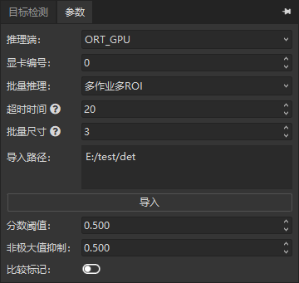
多作业¶
多个作业共享同一个深度学习工具,收集满足条件的图片后批量推理。
共享条件:推理端、显卡编号、批量推理设置、模型路径必须完全一致。
等待时间(毫秒):等待图片数量达到批量尺寸的最大时间,超时则将已有图片立即推理。
- 4 作业,批量尺寸 4,等到 4 张 → 直接推理
- 3 作业,批量尺寸 4,等不齐 → 等到超时再推理
- 5 作业,批量尺寸 4,等到 4 张 → 立即推理,剩下 1 张继续收集
注意:开启批量推理后,单个工具显示的耗时为整批的推理耗时,可能比开启前更高,但平均到每张图速度更快。
多作业多 ROI¶
上述两种逻辑组合:跨作业收集 ROI 一起批量推理。
调优建议¶
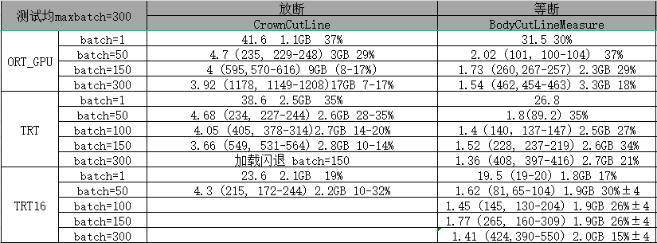
- CPU 推理端在不同批量尺寸下速度差异明显,建议测几组找最优批量尺寸 + 等待时间
- GPU 推理端可增大批量数量提速,也可开启更多模型并行计算来提高每秒帧数
深度学习加速服务¶
- 授权 ID:997
- 配套加速服务可让批量推理速度和资源利用率进一步提高
- 显卡运算量较小时单独使用容易出现耗时不稳定,开启加速服务后耗时稳定性显著改善
- 在工具栏可手动启动/停止服务
推理线程设置¶
CPU 推理深度学习时(如硅棒工具 3 等场景),可通过设置线程数限制 CPU 资源占用,避免单工具吃满整机。
Windows 系统电源与显卡性能设置¶
为了让 GPU 推理稳定发挥性能,强烈建议:
-
电源计划改为「卓越性能」:控制面板 → 电源选项
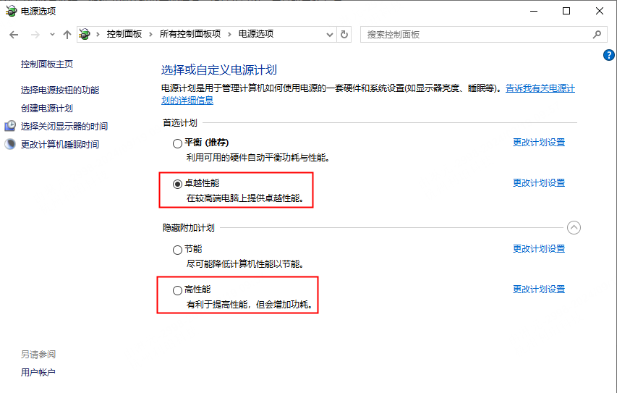
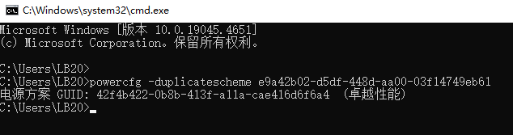
如果没看到「卓越性能」,在 cmd 中执行:
再回到电源选项里勾选
-
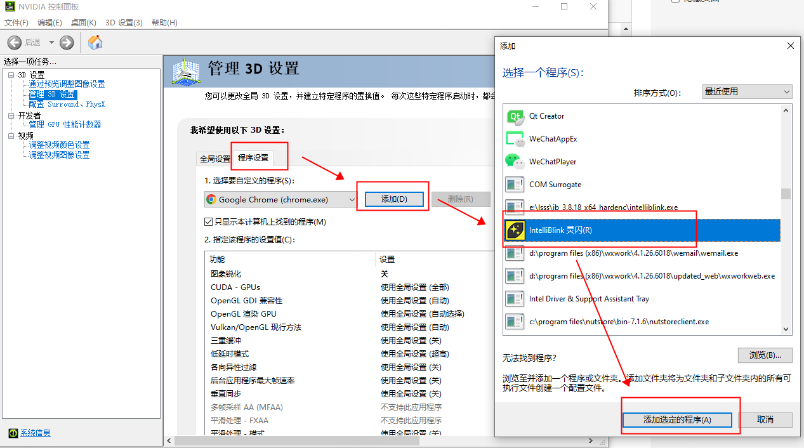
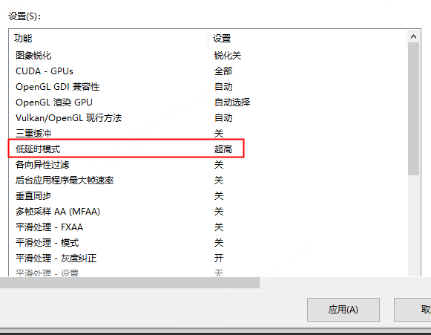
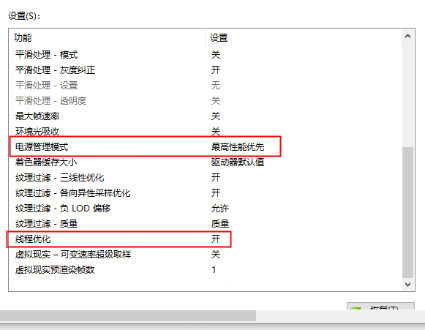
显卡性能模式:NVIDIA 控制面板 → 管理 3D 设置 → 电源管理模式 → 选「最高性能优先」
-
关闭显卡驱动自动更新:避免运行中的程序受版本变动影响
-
NVIDIA 显卡不接显示器:让显卡专心给推理用,不被桌面渲染分心
- 设置后 重启电脑 并确认三项设置仍生效
实测:100fps 帧率下单张推理 ≈ 3 ms,5fps 帧率下单张 ≈ 4 ms(连续负载比间歇负载更省)。
推理耗时优化清单¶
实际项目中如需进一步优化耗时,可逐项尝试:
- 在 最终部署的硬件配置 上做耗时测试,避免开发机和现场差异
- 多个推理端对比测速选最优
- 完成 Windows 电源 + 显卡性能设置 + 加速服务三项基础调优
- 减小模型输入尺寸(在精度可接受前提下)
- 把一个大 ROI 拆成多个小 ROI 走批量推理
- 把图片拆给多个作业批量推理(模型共享,存在等待开销)
- 把图片拆给多个作业但 关闭批量推理 走并行(模型不共享,占更多内存/显存,无等待开销)—— 例:单张 OPENVINO 平均 23 ms,3 作业并行总耗时 40 ms(人均 14 ms)
模型尺寸对应关系¶
- 深度学习工具内部:会先把 ROI 区域图片缩放到模型输入尺寸做推理,再把推理结果反向缩放回 ROI 原始尺寸
- 例:模型输入 100×100,ROI 区域 200×200 → 自动缩小 2 倍到 100×100 推理 → 结果再放大 2 倍对应 200×200 输出
- 缩放工具 → 深度学习工具:画布显示对应原图尺寸,深度学习输出尺寸对应缩放后的图
- 例:ROI 200×200 → 缩放工具 0.75 倍 → 150×150 → 深度学习内部缩到 100×100 推理 → 推理结果对应 150×150,画布显示对应 200×200
常见问题¶
模型导入后改参数不生效?¶
「导入按钮上方」的参数 → 导入前设置;导入后修改需重新导入模型才生效。 「导入按钮下方」的参数 → 导入后即时生效。
用 TRT 推理结果异常(出现错框或 NaN)?¶
升级 IntelliBlinkAI(山君)到 ≥ 2.8.3.0,重新导出模型即可。
ORT-GPU 批量推理偶尔耗时暴增(正常 1s 内,异常 6s 左右)?¶
ORT-GPU 在第一次见到某个批量数量时会有内部预热等待,之后再出现就不会等。
举例:第一批 4 张(等待+推理),第二批 4 张(推理),第三批 3 张(等待+推理,因为 3 是新数量),第四批 4 张(推理),第五批 3 张(推理)。
→ 有 GPU 优先用 TRT,不存在此问题。
TRT 加载几分钟后红框、加载失败?¶
- 先排查环境:用批量尺寸 1 + 输入尺寸小的小模型,看是否能加载成功
- 环境没问题就是 批量尺寸太大、显存不够,调小批量尺寸
替换模型文件后推理结果还是旧的?¶
- 模型已加载时替换文件不会自动重载,必须重新导入模型
- TRT 推理端要把对应的缓存文件夹(
.<模型名>.cache.trt)也删掉,再重新导入
CPU 推理两次耗时不同(第二次更短)?¶
即使设了卓越性能也会出现,与 Windows 调度有关:间歇运行耗时增长,连续运行(CPU 有空闲)耗时下降。例如 4 个相同模型 10fps 时平均 45ms,提到 20fps 后耗时明显下降。
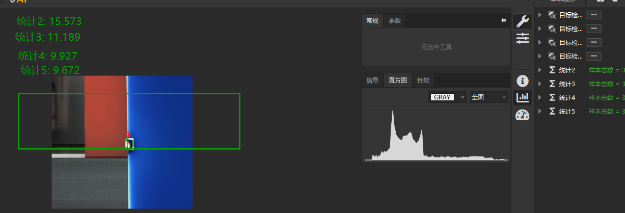
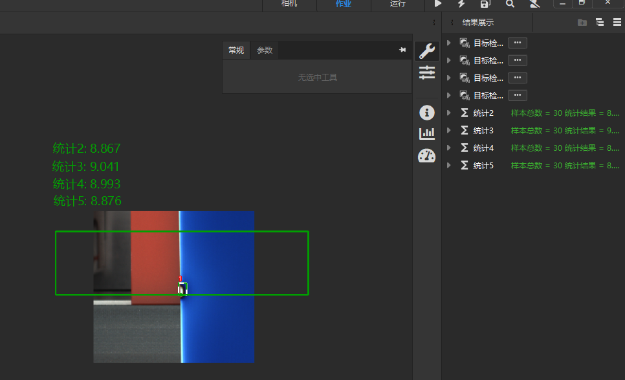
选 ORT-GPU 推理端,模型加载失败?¶
- 先确认 NVIDIA 显卡驱动已安装
- 然后安装匹配的 CUDA + TensorRT 包到灵闪目录(具体版本与显卡算力匹配,详见 AI 扩展包安装说明)
GPU 推理仅帧数不同导致单张耗时差异大(5fps 17ms / 100fps 5ms)?¶
按本节「Windows 系统电源与显卡性能设置」做完三项基础调优 + 加速服务,并 NVIDIA 显卡不接显示器,重启后再测试。